Вернуться на страницу Публикации
![]()
© Eugene A. Petroff, 1999
(часть 7)
![]()
В этой статье
рассматриваются два подхода к созданию
бюджетных студий на базе персонального
компьютера. От того, какой из этих подходов
будет выбран в качестве отправной точки для
проектирования, и будут зависеть основные
характеристики вашей студии - ее стоимость,
качество звука, скорость и удобство работы...
В предыдущих стаьях
цикла были рассмотрены основные
отличия физической и виртуальной студий, те
требования, которые они налагают на выбор
компьютерного «железа» и звукового
оборудования, а так же, основные
технологические этапы создания
законченного музыкального продукта...
Эта статья продолжает рассказ о создании музыкальной композиции при помощи Cakewalk Pro Audio 9.0
![]()
После создания первичной партитуры (записи MIDI треков), начинается следующий этап – предварительное сведение и компоновка композиции. Если бы все ограничивалось только MIDI – мы бы очень быстро пришли бы к концу нашего повествования. Однако, сегодняшний уровень компьютерных технологий таков, что основной акцент приходится на работу с аудио-материалом. Что, собственно говоря, и вдохновляет все большие и большие массы музыкантов на приобретение компьютеров. Однако именно здесь – в аудио домене - новичка поджидают главные опасности. Дешевизна компьютерной аудиозаписи соседствует с большим риском испортить материал одной необдуманной операцией. Причем, очевидным это становится не сразу – неправильно сделанная (в технологическом аспекте, разумеется, а не в музыкальном) композиция будет приводить в восторг вас, ваших почитателей в лице друзей и близких, но принесенная с гордым видом на студию под бдительные очи профессионалов, окажется подвергнутой уничтожающей критике и остракизму. И поделом – ведь окажется, что вы не учли множество важнейших технологических нюансов, поднимающих звукозапись на профессиональный уровень. Попытки с налету методом тыка создать нетленку бесполезны. Смею заверить так же, что попытка взломать барьер качества при помощи вложения избыточных финансов тоже малопродуктивна. Компьютерная техника в руках папуаса мертва. Поэтому разберитесь с теорией всерьез и навсегда – иначе вам не стоит заниматься звукозаписью самостоятельно. Откуда черпать знания ? Академические курсы радиотехники, цифровой обработки сигналов, и курс высшей математики очень не повредят... Не очень это по вкусу вашей «гуманитарной» мызыкантской душе ? Тогда пожалуйста отучайтесь размахивайть цифрами из технических описаний на аудиоприборы и звуковые карты – каждая цифра имеет определенный смысл и не всегда оказывается, что –90 дБ лучше, чем –82, поскольку все это зависит от способа измерения, вида сигнала и прочее, прочее, прочее... Тем не менее, какую то осмысленность действий в процессе контакта с цифровой звукозаписью вам придется в себе воспитать и я попробую помочь этому...
Давайте
рассмотрим очень кратко физику процессов в
цифровой звукозаписи. Делать это в рамках
настоящего повествования придется
отрывочно, сосредотачиваясь только на тех
аспектах, которые хронически выпадают из
множества публикаций на эту тему. Поэтому я
не буду описывать, как производится
оцифровка аналогового сигнала, не буду
приводить формулы шумов и искажений для
идеального случая. Я расчитываю, что вы уже
это знаете, прочитав популярные (и не очень)
издания на эту тему. Мы сосредоточимся на
тех аспектах, которые важны для сохранения
именно высококачественного звучания при
работе с Cakewalk Pro Audio...
Первый вопрос – какую разрядность проекта выбирать ? 16 бит или 24 ? Я уверен, что большинство из вас не задумываясь ответят – конечно 24 ! Ведь известно, что чем выше разрядность, тем меньше уровень шумов и искажений в малых сигналах. Обычно «цифровой» характер звучания приписывают именно недостаточной разрядности. Но я задам встречный вопрос – звучаните компакт-дисков в их лучших образцах вас удовлетворяет ? Вас устроило бы звучание вашего проекта на таком уровне ? Да ? Тогда подумайте о том, что нет ни одного компакт-диска с параметрами иными чем 16 бит / 44 кГц. А коль так, то сам по себе формат достаточен для создания звучания приемлемого качества. То есть, все необходимые компоненты звука в этом случае сохраняются. Но откуда же берется «цифровой звук» ? - спросите вы... Отвечу, но только не сразу, а по порядку – всяких монстров и монстриков, пожирающих вожделенное качество звучания в цифровых дебрях бегает немерянно. Вот мы и будем отстреливать их поодиночке.
Самое важное заблуждение, которому подвержен буквально весь мир, это вера в наличие «аналоговой» звукозаписи, которая якобы значительно лучше «цифровой». Но позвольте спросить – а где в природе вы найдете НЕКВАНТОВАННЫЙ звук ?? Звуковая волна – это процесс, живущий в некой упругой среде, который принято описывать аналоговыми математическими формулами. Но ведь в реальности сам воздух состоит из дискретных молекул, а аналоговая математическая модель, приближенно описывающая звуковую волну – это фикция, виртуальность... Звучит то не формула – в барабанную перепонку нашего уха стучатся отдельные молекулы, суммарный механический импульс от воздействия которых мы и воспринимаем как звук. Пойдем дальше в нашем анализе – после преобразования механической волны в электрическую, как более пригодную для хранения и передачи по дальним каналам связи, мы имеем в качестве носителя звука электрический ток. А электрический ток по своей физической природе тоже чисто цифровой ! Электроток – это процесс движения электрических зарядов, а попробуйте ка мне найти электрический заряд, меньший чем электрон !! Налицо квантование по амплитуде (по одной из координат, которыми задается звуковая волна). Квантование по скорости движения зарядов тоже налицо – пространство дискретно, как учит нас квантовая физика. Значит и в электрической форме звук квантован (дигитализирован или оцифрован, другими словами) – причем, уже как минимум дважды (первый раз – в акустической волне, второй раз – в электрической).
Таким образом оказывается, что для нас важно не то, «цифровой» звук или «аналоговый», а то, с какой разрешающей способностью в мелких деталях волны мы его храним, передаем и воспроизводим. Так называемая «аналоговая» звукотехника работает с сигналами, в которых разрешение, обусловленное квантовой природой материи, много ниже шумов, помех и прочих храктерныъх процессов НЕКВАНТОВОЙ природы. Хотя, справедливости ради, надо сказать, что, к примеру, шумы магнитной звукозаписи вполне квантовые – шумят магнитные домены (разумеется, это высказывание, слишком упрощает реальное положение вещей, но оно показывает наличие квантовых эффектов в звуке и на макроуровне). И все эффекты, которые принято приписывать «цифровым» системам в противовес «аналоговым», просто связаны с конкретной разрешающей способностью данной системы.
Итак
первый монстр, на отстрел которого я вам
ассигную лицензию, называется ТРАНКЕЙТ (от
английского слова truncate
– обрезать). Именно этот монстр первым
пожирает качество в процессе «квантизации»
- первичном преобразовании в АЦП на входе
вашей звуковой карты. Для того, кто знаком с
двоичной арифметикой - «музыкой нулей и
единиц» - я мог бы привести пример в
двоичном изложении. Однако, я знаю, что
значительная часть музыкантов не очень то
представляет себе, как все это можно
посчитать, имея только две цифры – 0 и 1.
Пэтому попробую привести примеры из
области более привычной каждому из нас –
десятичной математики, которую мы все
успешно (или не очень) осваиваем в школе.
Итак, представьте себе, что каждое значение
сигнала можно измерить дорогим
высокоточным прибором - пусть, к примеру, это значение
будет для очередной выборки равно 1.53967239045
Вольта. Мы имеем данное
значение, представленное 12 разрядами
ДЕСЯТИЧНОЙ шкалы. Но точность АЦП на входе в
вашу звуковую карту всего 4 десятичных
разряда (0.001%) и указанная выборка будет
представлена числом 1.539. Остальные цифры
будут отброшены – это и есть транкейт !
Ошибка транкейта в данном случае составит
0.00067239045 В. Казалось бы, ничего страшного –
величина очень малая. В общем то, да. Но это
если транкейт производится однократно, как
в случае первичной оцифровки. Гораздо хуже,
когда транкейт происходит в процессе
математических вычислений – тогда ошибка
каждого этапа вычислений накапливаясь,
может стать весьма значительной. «Два пишем
- три на ум пошло» - вот если эти «три»,
которые на «ум пошли» отбрасывать (а так
происходит в процессорах с недостаточной
разрядностью представления промежуточных
данных), то конечный ответ может оказаться
существенно другим. Тем то и опасен
транкейт – он выползает незаметно для
пользователя и целиком находится на
совести программиста, написавшего
программу обработки. Если запоминать с
нужной точностью все промежуточные
результаты вычислений, это сильно замедлит
работу программ, поэтому абсолютно все
современные программы используют
внутренний транкейт при обработке звука. Но
вот порог, при котором от чисел отрезается
по мелкому кусочку, в каждой программе свой
– этим и объясняется заметная на слух
разница в звучании различных программ, а
так же пресловутая разница в звучании
дорогих цифровых «железок» по сравнению с
их компьютерными аналогами. Дело в том, что
в «железных» обработках используются
быстродействующие спецвычислители (DSP),
которые оптимизированы под работу со
звуковыми процессами и при сопоставимой
скорости используют большую глубину
разрядности внутренних вычислений. Тем не
менее, это не является доказательством того,
что на компьютере невозможно получить
эквивалентное качество звука – скорости
современых компьютеров стремительно
растут и это способствует такому же
стремительному повышению качества работы
компьютерных обработок (в их новых релизах
– старые просто работают быстрей, но и на
новом компьютере их точность определяется
алгоритмом, который заложили разработчики).
Очень
важно понимать, где и когда в вашей системе
происходит транкейт. Например, самое узкое
место – это сохранение файлов (аудиотреков)
на жесткий диск. Фактическая разрядность,
которую вы выбираете в момент создания
проекта, относится в первую очередь именно
к разрядности файлов, использованых для
сохранения каждого из аудиотреков. А вот
математическая обработка может быть в
любом случае одинаковой. Во всяком случае, у
меня сложилось мнение, что аудиодвижок в
Кейквоке для обоих разрядностей проекта –
16 и 24 бита – один и тот же. Ведь гораздо
проще написать математику по максимуму, не
задумываясь о встраивании «переключателей»,
учитывающих разрядность даных и обсчитать
16 бит с той же конечной точностью, что и 24.
Просто в конце вычислений – в момент
сохранения даных на винчестер – будет
произведен транкейт с указанным значением.
Другой обитатель причудливого мира цифровых технологий, которого вам придется часто звать по имени – это дитер (от английского dither). В отличие от транкейта – «злого цифрового монстра» - дитер ваш друг и союзник и вам часто придется звать его на помощь. В чем физический смысл этого термина ? Точный и строгий ответ уведет в математические дебри, поэтому попробуем разобраться с этим «зверем» на пальцах.
|
Рис.1а |
|
Рис.1б |
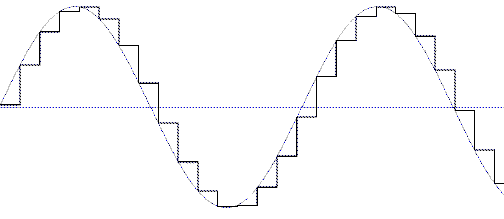
Взгляните
на рис.1а – здесь представлен принцип
амплитудного кодирования (АК) мгновеннного
значения сигнала. Эти ступеньки вам должны
быть хорошо знакомы, так как ни одно
популярное издание, затрагивающее вопросы
звукозваписи, не обходится без них. Теперь
взгляните на рис.1б – он илюстрирует
принцип широтной модуляции (ШМ), которая не
менее успешно может быть использована для
передачи сигнала с изменяющимся значением.
Ведь среднее значение импульсного сигнала,
ширина которого не равна длительности
одной выборки, будет пропорционально
именно ширине, если амплитуда постоянна.
Поэтому достаточно высококачественный
звуковой сигнал может быть передан и в
однобитном формате ! Только обратите
внимание, что в этом случае ступеньки
кодирования размещаются во временнОй
области. Это накладывает следующие
ограничения на систему с однобитным
кодированием – частота следования
кодирующих импульсов должна быть в
соответветствующее число раз выше частоты
квантования звука. Например, для
кодирования с качеством эквивалентным 8-разрядному
ИКМ (то есть, привычному амплитудному
кодированияю) тактовая частота должна в 256
раз превышать частоту дискретизации. Для 16-разрядного
кодирования это составит уже 65536 раз. То
есть, в случае формата 16/44 тактовая частота
должна быть не ниже 2890 мегагерц ! Это, мягко
говоря, несколько превышает возможности
современной техники. Тем не менее,
последовательное кодирование широко
применяется в современной
звуковоспроизводящей технике – именно
простота конструкции преобразователей
такого типа, и как следствие, крайне низкая
их стоимость и позволили нам иметь их в
своих компьютерах. Да и аппаратура класса
ХайЭнд тоже построена практически на
конвертерах бит-стрим.
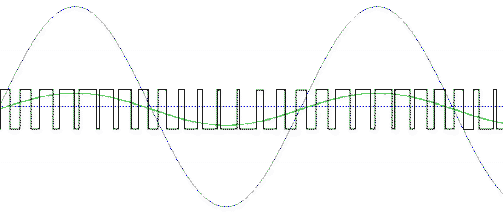
Подобные преобразователи работают
следующим образом – параллельный поток
разрядностью в 16 бит (или 18, или 20, или
24 – сколько указано в документации на
конкретную микросхему) преобразуется в
последовательный поток. Само
преобразование обеспечивается чисто
логическими элементами – без дорогих
прецизионных резисторов – и именно это
обуславливает крайне низкую цену
современных преобразователей. Разумеется,
тактовая частота не превышает нескольких
мегагерц – и на выходе мы слышим типичный «китайский»
звук (знакомый вам по заполонившим мир
китайским поделкам). В более дорогих
моделях преобразователей используются
более сложные алгоритмы, сочетающие и
параллельные, и последовательные принципы
преобразования – и качество таких ЦАП
зависит от сложности алгоритмов, что
естественно сказывается на цене. Но, тем не
менее, далего не всегда истинная
разрядность преобразованного сигнала
соответствует номинальной – той, которую
данная микросхема принимает по входу. Про
это надо помнить всегда и реально оценивать
возможности 20- или 24-х битных аудиокарт...
Вернемся
теперь к дитеру – после легкого экскурса в
область принципов кодирования звука,
принцип работы дитера становится яснее. Это
такой прием, при котором увеличение общей
разрешающей способности цифрового тракта
звукопередачи достигается специальным
кодированием младших разрядов. Разумеется,
в силу того, что оверсэмплинг (повышение
частоты квантования) в данном случае не
используется – формат записи остается
прежним - повысть разрешение можно не для
всех частотных компонент. То есть,
улучшение качества средних и нижних частот
достигается за счет ухудшения
динамического диапазона верхних частот.
Однако, физиологические особенности слуха
человека таковы, что повышенное разрешение
нужно именно в середине диапазона, а на
верхних и нижних частотах оно может быть
существенно более низким.
С формальной точки зрения дитер
перераспределяет помеху от цифровых
импульсов к более высоким частотам.
|
|
| Рис.2а. Транкейт |
|
|
| Рис.2б. Дитер |
Вплотную
к дитеру примыкает нойс-шейпинг (noice
shaping) –
способ, при котором при помощи
дополнительного шума снимается цифровой
призвук. Платой за уменьшение чисто
цифровых искажений является некоторое
увеличение шумов в обработанном таким
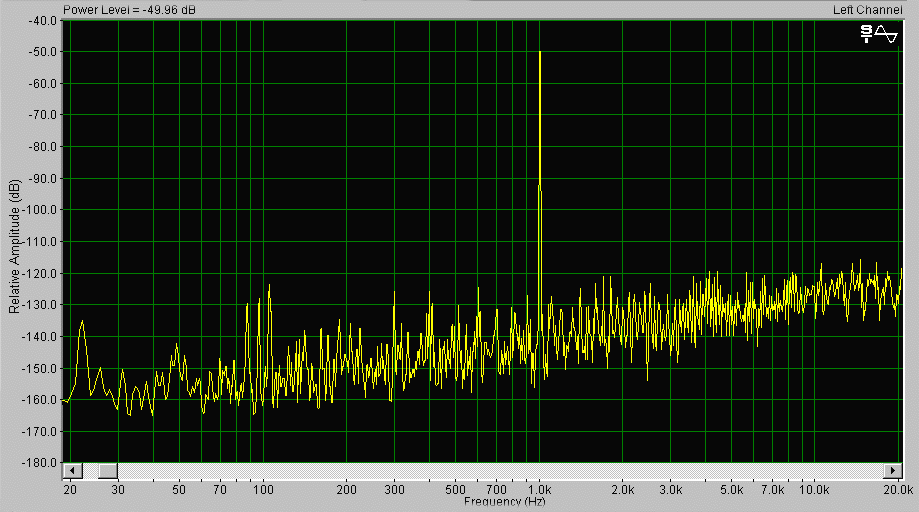
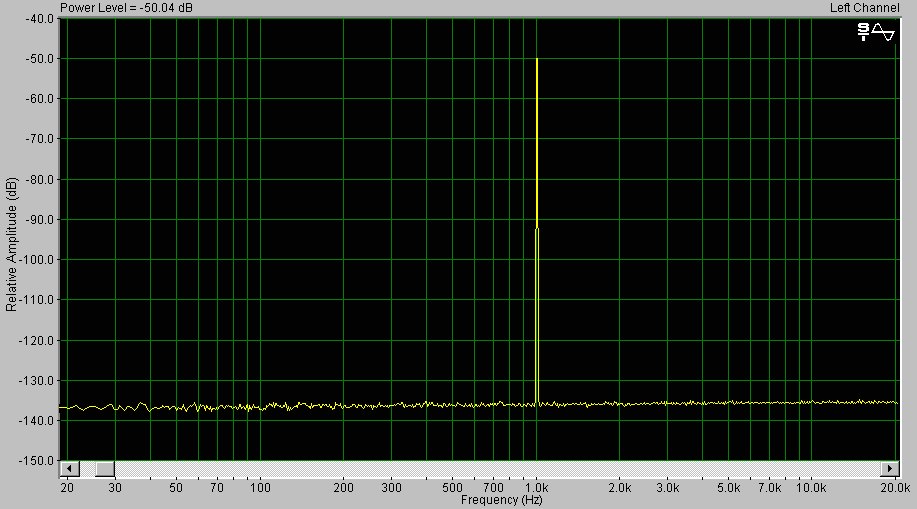
образом сигнале. На рис.2а представлен
спектр сигнала с транкейтом, а на рис.2б –
тот же сигнал, но обработанный дитером и
нойс-шейпингом. Обратите внимание, на то,
что флур (floor
– пол, или, в данном случае, основание
спектрограммы) становится ровным, а не
линейчатым. Такой характер сигнала
приближает его к аналоговому – с
улучшением детальности
звучания тихих звуков, а так же сохранением
принципа суперпозиции (независимости)
сигналов малой и большой амплитуды. В
обычной цифровой системе (с транкейтом)
сигналы большого уровня подавляют сигналы
малого уровня, и именно это «иссушает»
звучание, делает его более плоским и
утомительным для слуха («антиэкологичным»).
Обратите внимание на характерный всплеск
шумов в области самых верхних частот – это
и есть действие нойс-шейпинга и дитера.
Причем, если вы используете более высокую
частоту квантования, то этот пик может быть
вынесен вообще за пределы слышимого
диапазона. Например, в формате CD
(16/44) запас для шумового перераспределения
всего 2 килогерца (от 20 до 22 кГц – от верхней
границы слышимых частот до частоты
Найквиста), в формате DAT
(16/48) этот запас возрастает вдвое (от 20 до 24
кГц – что составляет 4 кГц против 2 в
предыдущем случае), а для продвинутого
формата 16/96 он оказывается вообще 28 кГц, то
есть в 14 раз ! Одно это способно повысить
разрешающую способность 16-битного тракта
до эквивалентного разрешению 20...24-битного
ИКМ... И именно правильным и обоснованным
применением этих «улучшайзеров»
профессионалы добиваются лучшего звучания
своих композиций. Но не будьте наивными –
не суйте их без разбора куда ни попадя.
Неумеренность здесь вредна, как и в любом
другом случае – любое лекарство в
лошадиных дозах превращается в свою
противоположность и вместо лечения просто
убивает.
Прежде,
чем вы приступите к работе над своими
опусами, поэкспериментируйте с дитером и
нойс-шейпингом. Методика достаточно проста.
Воспользуйтесь программой Sound
Forge и сгенерите при ее
помощи синусоидальный сигнал частоты 1 кГц
с уровнем –20 дБ (Tools/Synthesis/Simple…).
Затем скопируйте его во второе окно и
уменьшите его громкость в обоих окнах на 48
дБ, причем в первом окне сделайте это так,
что бы происходил транкейт. Для этого
воспользуйтесь командой Process/Volume...,
где и задайте параметр уменьшения
громкости –48 дБ. Во втором окне уменьшение
произведите при помощи цепочки эффектов,
выставленных в DirectX
Audio Plug-In
Chainer.
Эффекты должны быть такими – первым Waves
Q10 Paragraphic
EQ, а следом за ним Waves L1
Ultramaximizer+.
Эквалайзер вам понадобится для того, что бы
уменьшить уровень на 48 дБ. Для этого
сдвиньте до упора вниз движки федеров In
и Out в Q10.
Ультрамаксимайзером вам придется
пользоваться впоследствии часто, поэтому
разберитесь с ним повнимательней. В нем
надо выбрать пресет IDR type1/Ultra,
no limiting
– этот пресет обеспечивает только дитер и
нойс-шейпинг на выходе примочки при
выклеченной динамической обработке. После
того, как вы обработаете указанным образом
сигналы в обойх окнах, надо востановить
прежний уровень. Для этого вам придется
последовательно по три раза применить
увеличение громкости, так как предельное
повышение не может быть более +20 дБ. Поэтому
в двух первых операциях поднимаете на 20 дБ,
а в последней уменьшите увеличение
громкости до +8 дБ. Это скомпенсирует
первоначальное уменьшение
-48 дБ. А теперь послушайте оба сигнала –
с транкейтом (простой Volume)
и с дитером (Q10
+ L1). Не
правда ли – разительная разница ? Можете
так же взглянуть на спектрограммы –
сравнение явно не в пользу транкейта (рис.2а
и 2б)
Обратите
внимание – во втором случае использовалась
одна важная техническая особенность
звуковых систем, существующая на платформе IBM
PC / Windows.
Передача сигнала между отдельными
плагинами по технологии DirectX, являющейся частью
стандарта DirectShow,
всегда производится в максимальном формате
– 32 бита ! Эти 32 бита разделены на две части
– 24 бита значение, и еще 8 бит – порядок, то
есть, производится передача в формате с
плавающей запятой. Но для этого плагины
должны быть соединены между собой
непосредственно (например, в данном случае
через программу связи Audio
Plug-In
Chainer). Если
обрабатывать сэмпл теми же плагинами по
очереди независимо, то при сохранении на
винчестер промежуточного результата
неизбежно произойдет транкейт и результат
окажется таким же, как при простой операции Volume.
Можете проверить это самостоятельно.
Именно благодаря этой особенности в 16-разрядной
программе Sound Forge вполне успешно можно
заниматься мастерингом (да простят меня те
специалисты, котрые считают, что на
компьютере мастеринг невозможен по
определению – под мастерингом я понимаю те
технологические операции, которые
происходят между получением
окончательного микса и записью фонограммы
на тиражный носитель; и даже если тиражным
носителем является нарезанная матрица, на
которой вы отдадите вашу демозапись
продюссеру или распространите ее среди
друзей, то по технической сущности это
именно полноценный мастеринг, а о качестве
оного разговор должен быть совершенно
отдельный).
Должен
так же предупредить, что далеко не все
плагины являются полноценными – многие из
них на поверку оказываются всего лишь 16-разрядными.
Это определяется только разработчиком –
сам по себе канал передачи не
перестраивается и ограничение задается
программистом алгоритма. Поэтому не мешает
протестировать каждый новый плагин на
разрядность. Для этого существуют
специальные тестирующие плагины – вы
устанавливаете тестер непосредственно
после проверяемого плагина и в процесе
работы следите за индикатором поразрядной
активности. Примером таких плагин могут
послужить dxfilter (разработчик Дмитрий
Горелов - Dmitry Gorelov (2:5030/353.42@Fidonet)) и AnalogX
BitPolice v1.02 (http://www.analogx.com).
На сайте AnalogX
вы, кстати, сможете найти множество других
свободно распространяемых плагинов,
которые окажутся весьма полезными для
вашей работы.
Ну что ж – эта парочка «цифровых монстров» оказалась на удивление доброй и полезной. Но это вовсе не означает, что злых и вредных чудовищ в цифровых чащобах больше не обитает. Обитают, да еще какие ! Например, джиттер (jitter) – дрожание фронта цифрового импульса. Наряду с транкейтом, этот монстр в наибольшей степени ответственен за неприятности цифрового звучания. Правда, для тех условий, которые сложились в Персональной Студии, он может почти не проявляться, особенно, если вы работаете в виртуальной, а не физической студии (напомню, что принципиальные отличия этих типов рассмотрены в первой статье цикла). В виртуальной студии единственное место, где джиттер способен показать зубы, это входной оцифровщик (АЦП вашей звуковой карты). Причем, вы мало сможете повлиять на ситуацию – все зависит только от качества выполнения звуковой карты. Правда, если вы используете цифровой вход, а АЦП у вас внешний и подключается цифровым кабелем, вот тогда нужно быть внимательным. Аналогично и в физической студии – джиттер появляется на линиях ЦИФРОВОЙ связи – и если у вас Darla, то о джиттере вы можете не беспокоиться – все в руках разработчиков этой карты. А вот если вы используетье внешние ЦАПы – то тут уже многое будет зависеть от вас, то есть, от того, насколько правильны ваши цифровые кабели. Поскольку этот вопрос очень сложный, то сути его мы касаться не будем – об этом более уместно разговаривать на страницах схемотехнического журнала, а не музыкального. Обращу только ваше внимание на то, что при полностью виртуальной технологии ваша продукция будет полностью свободна от джиттера – ведь после первичного преобразования передача данных внутри компьютера идет на совершенно иных принципах, чем на линии связи и джиттер исключается в зародыше. Для меня этот фактор является несомненным доводом в пользу полностью виртуальных технологий.
|
|
| Рис.3а |
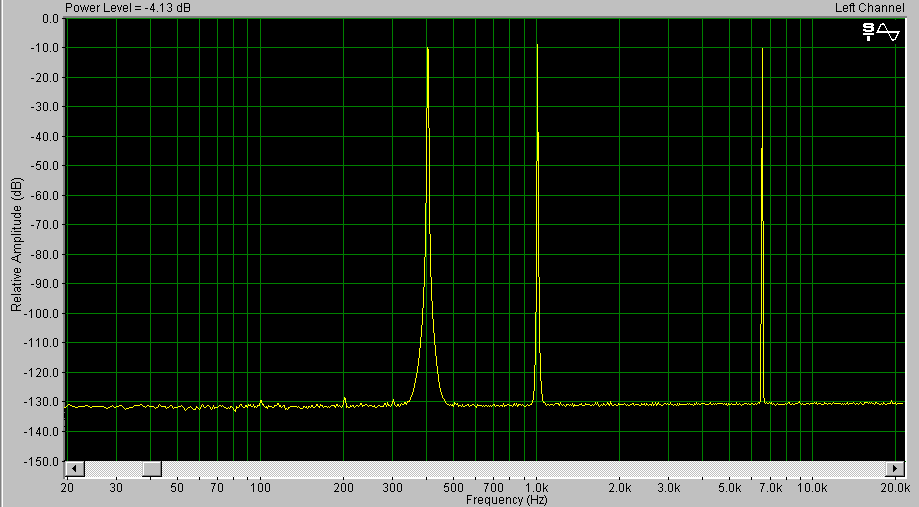
Я перечислил не все проблемы цифровых технологий – разговор о них мы продолжим в следующей статье цикла. Мы так же рассмотрим, каким образом правильно распорядиться внутренними ресурсами программ, для того, что бы качество звучания было максимально возможным. О том, что современные программы позволяют обрабатывать звук с достаточной точностью, свидетельствует рис.3а. На нем изображена спектрограмма процесса микширования трех чистых тонов (400, 1000 и 6500 Гц) с уровнем –6 дБ, размещенных в отдельных аудиотреках Cakewalk Pro Audio 9.02. Как видно из графика, в получившемся суммарном сигнале совершенно отсутствуют какие то компонеты, являющиеся искажениями (как гармоническими, так и интермодуляционными). Это результат сведения non real time – через внутренний микс программы.
|
|
| Рис.3б |
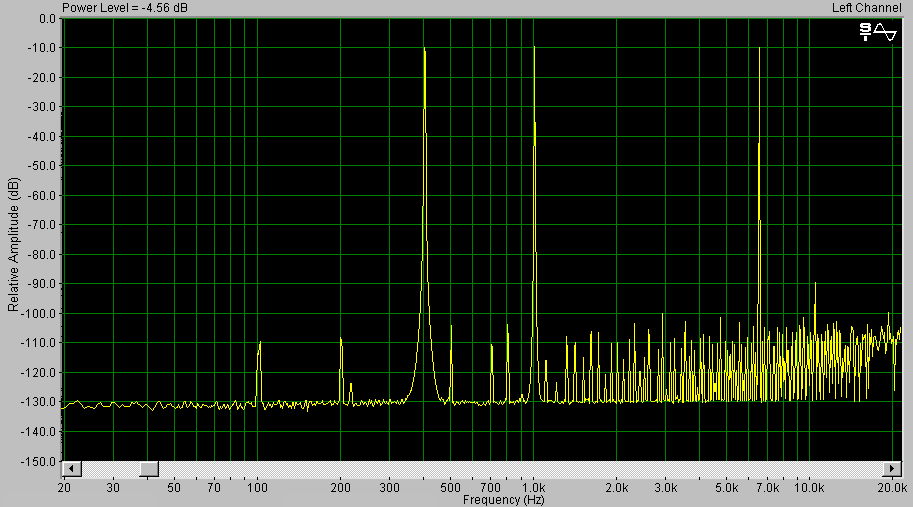
В качестве аргумента в выборе типа студии – физической или виртуальной - на рис3б приведена спектрограмма того же смикшированного сигнала, но полученного в режиме real time - пропущеного через звуковой тракт аудиокарты (SB Live! Value). Можете сравнить его с рис.3а – наличие цифровой «бороды» характеризует возможности каждой из технологий. Разумеется, я не призываю к бездумному переходу только на виртуальную технологию – для многих звукорежиссеров возможность рулить натуральными фейдерами в процессе сведения, а не тыкать мышкой в виртуальные кнопочки, есть важнейший фактор, вполне преодолевающий некоторое ухудшение качества, естественное для технологии физической студии.
В качестве домашнего задания рекомендую вам проделать подобные тесты – получить в Sound Forge максимально очищенный сигнал и смикшировать его в кейквоке или кубейсе, пытаясь получить такую же «стерильную» спектральную характеристику. Уверен, что у большинства из вас это сразу не получится, но если вы не будете напрягать свое серое вещество в поиске правильных решений, то никогда не овладеете премудростями качественной звукозаписи. В следующей статье я приоткрою некоторые секреты достижения такого качества и вы сможете сравнить результаты собственных усилий с «контрольным ответом». Не исключаю, и более того, желаю вам найти собственные технологические изюминки. Главное, что бы результат достигался осознанием проблемы и выбором подходящих способов действия...
Если у вас возникают вопросы, то вы можете задать их мне по телефону (095) 248-3149 каждый вторник с 12 до 18. Убедительная просьба быть внимательными и не звонить в другое время – вы создате проблемы совершенно посторонним людям.
Май 2000
![]()
Вернуться на страницу Публикации